
- Log in to the Azure portal at https://portal.azure.com➢ navigate to the Azure Stream Analytics job you created in Exercise 3.17➢ select Query from the navigation menu ➢ enter into the query window the query in the StreamAnalyticsQuery.txt file located in the Chapter07/Ch07Ex09 directory on GitHub ➢ click the Save Query button ➢ and then start the job.
- Download the brainjammer‐legacy.zip file from the Chapter07/Ch07Ex09 directory on GitHub ➢ extract and execute the brainjammer.exe application ➢ and then use the csharpguitar‐brainjammer‐pow‐legacy‐schema‐drift.json file as input. Note that the stream was placed into the ADLS container, not into your Azure Cosmos DB container; notice also there is no column for MODE in the output (see Figure 7.38).

FIGURE 7.38 Handling schema drift in a stream processing solution in ADLS
- Download the brainjammer‐current.zip file from the Chapter07/Ch07Ex09 directory on GitHub ➢ extract and execute the brainjammer.exe application ➢ and then use the csharpguitar‐brainjammer‐pow‐current‐schema‐drift.json file. Note that the stream was placed into the Azure Cosmos DB container, not into your ADLS container; notice also the MODE property and value exist in the output (see Figure 7.39).
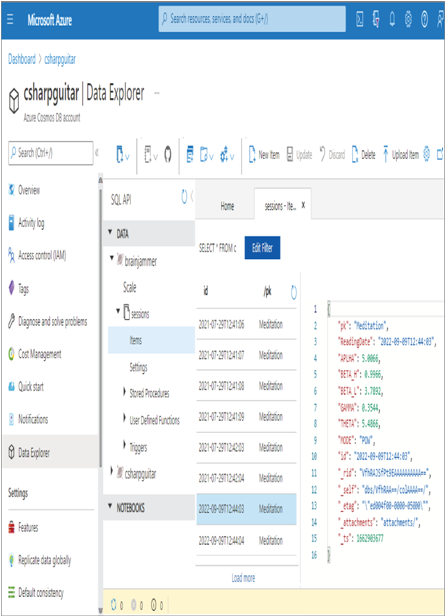
FIGURE 7.39 Handling schema drift in a stream processing solution in Azure Cosmos DB
- Stop the Azure Stream Analytics job.
The most critical part of Exercise 7.9 is the query. The first part resembles the following. Notice that the query includes the new addition of the schema, which includes MODE. However, MODE is neither selected nor provided by the devices that use the legacy schema.
A TRY_CAST function is not performed on ReadingDate, because it can be a data type of string or datetime. The next portion of the Azure Stream Analytics query uses the result in the BrainwaveResults dataset to format and capture the data in the necessary format. Notice that the original schema expected the data type of ReadingDate to be datetime. In the current schema that value will be a string. It is important to maintain that data type through this data stream, because downstream systems that use this data might break if for some reason the string value contained in ReadingDate does not cast to a datetime.
Therefore, the TRY_CAST function on the ReadingDate is performed and stored into the legacyBrainwaves dataset. It might also be the case that downstream systems would throw an exception if a new column was added to the result. MODE is not included in the SELECT statement and by consequence is not present in the output. The drifted schema requires a column named pk, because that is the partition key name that is expected in the Azure Cosmos DB. The SELECT statement contains the MODE column, and, as in the previous query segment, there is a WHERE clause. The WHERE clause manages the selection of data based on the existence of a value in MODE.
If MODE is null, then the row is selected into the legacyBrainwaves dataset but not into the currentBrainwaves dataset, and vice versa, whereas when MODE is not null, the row is selected and stored into the currentBrainwaves dataset but not into the legacyBrainwaves dataset. The final two lines of the query resemble the following:
SELECT Scenario, ReadingDate, APLHA, BETA_H, BETA_L, GAMMA, THETA
Notice that the selected columns are slightly different and are each stored into a different output alias. As previously mentioned, when a schema is changed, it is important that downstream systems that use that data not be impacted. If there is a change that cannot be managed, then all systems that use the data would need to be tested with the new data. This is considered a breaking change. Those kinds of scenarios have a great impact, as a lot of testing is required. It would be easier to output the current version to a new location and have the option to use the new data, if necessary, instead of forcing them to be updated. Finally, notice that the values following the FROM clause reference the dataset populated from the two previous subqueries.
Note that the two brainjammer.exe applications simulate an upgrade to the device that produces data. The data streaming to your Event Hubs endpoint would now have an increase in data variety caused by a schema drift. Your Azure Stream Analytics job, the datastores, and the downstream consumers who use the data must be able to adjust to these changes. Exercise 7.9 is just one example of how that flexibility can be realized. Azure Stream Analytics does not need a schema definition for input data streams. The columns and datatypes are inferred dynamically and are implicitly cast when needed. This is a very powerful tool, but it comes with some caveats. While performing Exercise 7.9, you learned that Cosmos DB is not very supportive of the datetime datatype. When a TRY_CAST was performed on the ReadingDate into datetime format, the output failed to be stored into the Azure Cosmos DB container. The error was a format not expected or supported. The insertion was successful only when the ReadingDate was a string. Had the platform implicitly cast this value to datetime, it would not work when being stored in Azure Cosmos DB.
Finally, the source code for each brainjammer.exe is stored on GitHub in the Chapter07/Ch07Ex09 directory. The difference between each code snippet is the addition of a JProperty to contain MODE into the JObject class, as shown here:
new JProperty(“MODE”, brainwaves.Session.MODE)
The Session class into which the JSON files are deserialized required the addition of a MODE property, as shown here:
public class Session
It is inevitable that content within data streams changes; therefore, it is very important to consider as many options as possible prior to developing your stream processing solution. Flexibility is paramount.


